Genome-Wide Association Studies of Cancer: Principles and Potential Utility
Genome-wide association studies (GWAS) have emerged as a new approach for investigating the genetic basis of complex diseases. In oncology, genome-wide studies of nearly all common malignancies have been performed and more than 100 genetic variants associated with increased risks have been identified. GWAS approaches are powerful research tools that are revealing novel pathways important in carcinogenesis and promise to further enhance our understanding of the basis of inherited cancer susceptibility. However, “personal genomic tests” based on cancer GWAS results that are currently being offered by for-profit commercial companies for cancer risk prediction have unproven clinical utility and may risk false conveyance of reassurance or alarm.
Genome-wide association studies (GWAS) have emerged as a new approach for investigating the genetic basis of complex diseases. In oncology, genome-wide studies of nearly all common malignancies have been performed and more than 100 genetic variants associated with increased risks have been identified. GWAS approaches are powerful research tools that are revealing novel pathways important in carcinogenesis and promise to further enhance our understanding of the basis of inherited cancer susceptibility. However, “personal genomic tests” based on cancer GWAS results that are currently being offered by for-profit commercial companies for cancer risk prediction have unproven clinical utility and may risk false conveyance of reassurance or alarm.
Until relatively recently, the field of medical genetics has focused on the identification and treatment of rare, single-gene disorders that are usually associated with a high-risk of a particular disease or trait. Since Watson and Crick’s groundbreaking explanation of DNA structure in 1953, our understanding of patterns of inheritance has progressed considerably. We now recognize that the genetic architecture of complex diseases such as cancer is probably better characterized by polygenic and multifactorial inheritance, wherein heritability is determined by the joint action of multiple genes and their interaction with environmental factors.
Technological advances have facilitated detailed interrogation of the human genome and moved investigations of genetic causation from linkage studies in high-risk cancer families to genome-wide association studies (GWAS). Through a hypothesis-neutral genome-based approach, GWAS compare common DNA variations in a large set of unrelated cases and controls to identify genetic variants associated with disease risk. Common genetic variations that contribute to susceptibility to more than 40 different diseases, including heart disease, diabetes, asthma, psychiatric disorders and inflammatory bowel disease, have been identified.[1]
GWAS have also been performed for most common malignancies and more than 100 genomic variants associated with risks of various cancers have been described. This unprecedented rapid amassing of new genetic risk variants associated with cancer risk has generated hope that these germ-line markers may also prove useful for cancer prevention, improve our understanding of cancer pathogenesis, and possibly direct treatment of patients. However, considerable scientific barriers must be overcome before these genomic data can meaningfully contribute to patient care. In this review we detail the role of genomic variation in cancer susceptibility and discuss the potential clinical implications of recent discoveries. We review warnings by professional societies and government advisory bodies regarding the use of genomic information to guide clinical decisions, with particular emphasis on the potential risks posed by for-profit, direct-to-consumer marketing of genomic risk panels.
The Genetics of Cancer Predisposition
Genetic linkage studies performed in the 1980s and 1990s identified a number of highly penetrant syndromes responsible for cancer predisposition within certain families. Molecular insight into breast-ovarian cancer (BRCA1/2), Lynch (mismatch repair genes), Li Fraumeni (p53) and Cowden (PTEN) syndromes, among others, has had a powerful impact on current clinical management of families affected by these syndromes. These syndromes, however, account for only a fraction of the familial risk of cancer, leaving much of the heritability of cancer unexplained.
Epidemiologic evidence provides strong support for a hereditary component to cancer. Twin studies demonstrating concordance for most cancers among monozygotic vs dizygotic twins and siblings,[2] and population studies of familial clustering,[3] suggest that genetic factors predispose to even environmentally induced diseases such as lung cancer. Using a candidate gene approach, pathways thought to be important in carcinogenesis have been investigated. In breast cancer, for example, a small number of candidate genes involved in the response to DNA damage (ATM,[4-6] CHEK2,[7-9] BRIP1,[10] and PALB2[11]) have been associated with a modest increase in breast cancer risk (approximately two-fold). It is estimated that these genes, in combination with the high penetrance but rare cancer-predisposition–syndrome genes such as BRCA, account for only about one-quarter to one-third of familial risk, with the remainder remaining unexplained.[12] One explanation for this seemingly “missing” fraction of heritable disease is the common variant common disease (CVCD) hypothesis,[13] which assumes that many different common genetic variants, each with a small effect size, collectively cause disease.
Recent developments, including the completion of the Human Genome Project, the HapMap Project, and the emergence of high-throughput genotyping, have allowed further investigation of this hypothesis, through the GWAS approach.
Experimental Design of Genome-Wide Association Studies
Genomic variation in GWAS reported to date is largely represented by single base pair changes known as single nucleotide polymorphisms (SNPs). Although structural genomic variations such as deletions, duplications, inversions, and copy-number variations also exist and can be measured, assessment of these more complex genomic changes are just beginning to be incorporated into large genome-wide studies. GWAS rely on the phenomenon of linkage disequilibrium,[14] wherein SNPs are not inherited individually but instead are in linkage disequilibrium blocks, with many nearby SNPs being highly correlated. This enables the selection of one SNP (the tag SNP) that represents up to 50,000 surrounding base pairs. Through the HapMap project[15] we have learned that genotyping sets of 500,000 to 1,000,000 tag SNPs can cover approximately 80% of all common SNPs in the genome.[16]
FIGURE 1


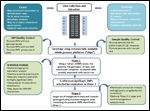
Design of a multistep cancer GWAS
These striking technological advances have facilitated GWAS studies using multistep designs (Figure 1). As large GWAS are often cost-prohibitive, a tiered, multistage approach is commonly used. In a simple two-stage design, all tag SNPs are tested during the first stage on a small subset of cases and controls, usually between 25% to 50% of total participants. During the second stage, significant SNPs, comprising approximately 10% of the SNPs tested, are genotyped on all remaining samples. The same sample of SNPs is then tested on the initial subset,allowing for a combined analysis.[17] For study designs with three or more stages, the significant SNPs are included for replication testing in different case-control sample sets.
A typical GWAS, containing 1,000 to 2,000 cases with often a larger number of controls, is powered to detect differences in common SNPs with an effect size of 1.5–2.0-fold. Importantly, some smaller GWAS reporting effect sizes of 1.1–1.3 must be interpreted with caution, as these studies may have been underpowered to detect such small differences. In fact, the detection of modest genetic effects with odds ratios of 1.3 or less and minor allele frequencies under 10% may require more than 10,000 cases and 10,000 controls for adequate statistical power.[18] Most recent significant findings have been for alleles with relative risks of 1.1 to 1.3, and their detection has required large, global, collaborative group efforts.
GWAS approaches require careful selection and accurate characterization of case and control participants. In breast cancers, for example, gene-expression profiling has defined different subtypes of breast tumors (eg, luminal, basal subtype) with variations in response to treatment and clinical outcomes. As we learn more about the heterogeneity of malignancy it may be necessary to perform individual GWAS for different subtypes of disease, to accurately detect underlying genetic heterogeneity. As an example, the 10q26 locus that maps to FGFR2 and has been implicated in a number of breast cancer GWAS, and is most strongly associated with the diagnosis of estrogen receptor (ER)-positive disease.[19]
GWAS for women with triple-negative breast cancer are ongoing and may demonstrate different genetic associations. A well-matched and carefully characterized control cohort is another key component of GWAS design that is a challenging but essential prerequisite for a precise study. For example, cases and controls must be well-matched to avoid population stratification, which can bias results due to differences in race or ethnicity of those with and without the disease of interest.[20-23]
Genome-Wide Association Study Interpretation
Analysis of GWAS data produces an odds ratio and P value for each SNP, but great care is required to avoid false-positive or false-negative reporting. A quality control ‘data cleaning’ is first performed to detect problems such as poor genotyping results or unexpected relatedness among participants. Allele frequencies among controls, for example, are compared with an accepted standard (Hardy-Weinberg equilibrium), as deviations from this equilibrium often indicate a methodologic flaw in the study. Population heterogeneity can introduce a bias in studies of participants with different ancestries, although a post-hoc principal components analysis can be performed to account for this.[24] Further stringent statistical analysis must be applied to account for the multiple testing performed in GWAS and is usually achieved using a Bonferroni correction, in which the threshold P value (usually 5 × 10-2) is divided by the number of tests performed (~500,000 depending on array used) resulting in a P value in the region of < 1 × 10-7.
Only associations between a SNP and an outcome of interest that fall below this threshold should be considered statistically significant, but despite this rigid approach false-positive results frequently occur, as evidenced by failure to replicate findings in subsequent studies using the same SNPs and similar populations. Despite optimal design and careful analysis, interpretation of GWAS results has been complicated by a publication bias whereby positive associations are preferably published.
Lessons From Genome-Wide Association Studies in Cancer
TABLE 1


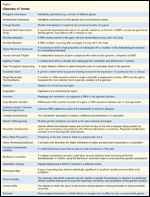
Glossary of TermsTABLE 2


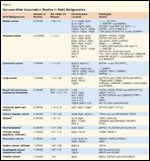
Genome-Wide Association Studies in Solid MalignanciesTABLE 3



Genome-Wide Association Studies in Hematologic Malignancies
Genomic variation has not yet contributed positively to patient management in cancer care; nonetheless, the 50-plus GWAS that have been performed for more than 15 malignancies have generated many interesting associations, stimulating widespread interest in the clinical utility of this tool. Breast cancer (nine GWAS),[25-33] prostate cancer (12 GWAS),[34-45] colorectal cancer (seven GWAS),[46-52] and lung cancer (seven GWAS),[53-57] have been extensively investigated, and similar studies have been performed in pancreatic,[58,59] gastric,[60] esophageal,[61] bladder,[62,63] testicular,[64,65] ovarian,[66] skin,[67-71] thyroid,[72] neuroblastoma,[73,74] brain,[75,76] and hematological cancers,[77-81](Tables 2 and 3). A detailed discussion of each study is beyond the scope of this manuscript, but some notable lessons have been learned from individual findings.
The 8q24 locus, first reported in Icelandic patients, is of particular interest.[42] It is located in a region containing no known genes (referred to as a ‘gene desert’) but has been associated with prostate, bladder, breast, and colorectal cancer, and the association has been successfully replicated in independent studies. It is possible that genomic variation at this locus marks a carcinogenic pathway common to many cancers, and recent evidence suggests a role in regulation of the myc oncogene.[82-84] A second locus at 5p15.33 has also been associated with multiple cancers. A multicancer study of > 30,000 cases and > 45,000 controls identified an association between the 5p15.33 locus and risk of lung, bladder, prostate, cervical, and basal cell cancer, with a trend towards a protective effect for cutaneous melanoma.[85]
Epidemiological studies have identified a higher incidence of aggressive prostate cancer in African-American men, and there has been much debate as to whether this represents a socioeconomic difference in how African-American men are screened and treated for prostate cancer or a distinct natural history. Recent GWAS data suggest that seven independent risk variants identified in the 8q24 region are more commonly associated with prostate cancer in African-American men, possibly suggesting a genetic link for this epidemiological observation.[86] The first GWAS in pancreatic cancer provided another example of genomic data supporting prior epidemiological observations.[87] Pancreatic cancer risk had long been associated with ABO blood type, and a SNP located in the first intron of the ABO blood group gene on chromosome 9q24 significantly increased the risk of pancreatic cancer by 1.2-fold.[59]
Cancer GWAS have also identified associations in genes encoding proteins known to be important in organogenesis and organ function. Prostate cancer GWAS have identified a number of significant associations between prostate cancer diagnosis and SNPs in genes that encode key products of the prostate; serum levels of micro-seminoprotein and a number of kallikreins have been identified as potential prostate cancer biomarkers, and GWAS have now offered associated genomic markers for further study.[34,35] In testicular germ cell tumors, in which genetic susceptibility is supported by an 8- to 10-fold and a 4- to 6-fold increased risk of disease in brothers and fathers of patients, respectively, the two GWAS both identified risk variants at 12p22,[64,65] a region that contains KITLG, which is necessary for germ cell development.[88] The risk variant at 12p22 has one of the highest associated risks of any GWAS, conferring more than a 2.5-fold increase in cancer risk. The only thyroid cancer GWAS performed to date identified two significant predisposing SNPs, one at 9q22.33 near FOXE1, which has been implicated in thyroid organogenesis, and the other at 14q13.3 near NKX2-1, a gene important in thyroid gland differentiation.[72]
GWAS in hematological malignancies have identified a number of predisposing SNPs for
chronic lymphocytic leukemia, non-Hodgkin lymphoma, and childhood leukemia[77-80]; however, in a study of myeloproliferative neoplasms (MPN) we noted an interesting finding. A somatic point mutation in JAK2 is commonly found in MPN, and the GWAS identified a germline SNP in this same gene that resulted in a three-fold-increased risk of developing MPN. This finding linked this germline and somatic variation, a finding similar to the I1307K APC variant and colorectal cancer.[81]
Melanoma GWAS have provided further results of biological interest. CDKN2A is a well-recognized high-penetrance melanoma susceptibility gene, and a recent GWAS associated an adjacent locus with increased risk of melanoma, confirming this as an important region in melanoma pathogenesis.[69] This same study reported a risk allele at 16q24, a region encompassing MC1R that is involved in cell cycle regulation, and this SNP was previously reported in a GWAS of hair color and skin pigmentation.[89] Significant associations with variants affecting hair, eye, and skin color were identified in another melanoma GWAS, confirming the ability of this approach to reflect underlying biology.[70]
Translating Genome-Wide Association Studies Into Clinical Practice
These examples and others in nonmalignant diseases provide evidence that GWAS can identify genomic variations associated with disease risk and known biology. Nonetheless, a systematic review of 260 meta-analyses of 160 SNP associations reported that there is insufficient scientific evidence to conclude that genomic profiles are useful in measuring genetic risk for common diseases or in developing personalized recommendations for disease prevention.[90]
Importantly, neither the clinical validity (accuracy of a test in predicting the clinical outcome) nor the clinical utility (risks and benefits resulting from the use of a test) of this approach have been established.[91,92] As an example of the challenge, consider the 1.26-fold increased risk of breast cancer associated with the risk allele in the FGFR2 gene.[25] This represents a 26% relative increase in risk over a lifetime, comparable to that conferred by delaying age of first pregnancy to more than 35 years, but without knowing an individual’s absolute risk this information is somewhat meaningless. Furthermore, it is unclear how to best combine risk alleles into a ‘multi-SNP’ prediction tool, and how to incorporate this approach into existing clinical models.
Even if the common variants identified lay within known genes, gene-gene interaction (referred to as epistasis) is poorly understood, and it is unknown if the relative risks associated with each SNP should be combined in an additive fashion or multiplicatively. Experimental multi-SNP models have been compared with predictive tools that use clinical variables alone. For example, in a modeling study, the addition of genotypes from seven breast cancer–associated SNPs to the National Cancer Institute’s Breast Cancer Risk Assessment Tool was of no clinical significance, with an increase in the area under the receiver operating characteristic curve from 0.607 to 0.632.[93] More recent studies have supported only a modest increased predictive accuracy of genomic risk panels.
Susceptibility SNPs have also been proposed as potential biomarkers to predict outcome after diagnosis, as they can be identified at time of blood draw, do not change over time (ie, are constitutional), and are dichotomous (ie, do not require adjustment or normalization). Breast-ovarian cancer syndrome offers an example of how germline variation can predict clinical course, with BRCA-associated ovarian cancer demonstrating an improved survival vs sporadic disease, with the reverse relationship having been suggested for BRCA-associated prostate cancer.
Genome-based prediction models in prostate cancer, in which nomograms incorporating clinical variables have had a less than satisfactory impact on patient management, have thus far offered only modest advantages. A number of studies have failed to associate susceptibility SNPs with meaningful clinical endpoints in prostate cancer,[94-96] or with overall survival in breast cancer. However, carefully designed GWAS of specific clinical endpoints would be required before dismissing genomic variation as a potential prognostic biomarker.
Finally, recent reports from clinical trials investigating poly (ADP-ribose) polymerase 1 (PARP-1) inhibitors in BRCA-associated malignancy provide the first example of successful targeting of germline genetic variation.[97] Genomic variation, either rare variants associated with specific disease or loci associated with different malignancies, such as 8q24, has the capacity to identify novel, potentially targetable pathways important in carcinogenesis.
The appeal of basing clinical decisions on the results of a blood or even saliva test is obvious. The current complex issues in the management of prostate cancer offer an example of how germline variation may one day contribute meaningfully to patient care. Despite recent results from two large prostate cancer screening studies, it is unclear if screening unselected patients is of benefit,[98,99] and it is difficult to identify populations at highest risk. In the absence of markers of increased risk, it is also not clear whether or not 5α-reductase inhibitors should be used for routine disease prevention.[100]
After diagnosis of prostate cancer, many men may not require treatment, but it is unclear how to best identify this cohort. For men with advanced, hormone-refractory disease, treatment options are limited and novel therapeutic approaches are urgently needed. It is feasible that germline variation could be used to identify populations appropriate for screening, prevention, and certain treatments. Such genetic variants may also lead to discovery of pathways important in prostate cancer pathogenesis, and the results from the prostate cancer GWAS completed to date begin to set the stage for such further studies.
The Current Promise and Peril of Clinical Translation
The potential of genomic approaches to have a significant impact on our understanding of disease biology is unquestioned, but the clinical relevance of genomic variation for most common disorders remains to be established. Recognizing the scientific merits as well as the limitations of GWAS, the American Society of Clinical Oncology has recently updated its policy statement on genetic (and genomic) testing for cancer susceptibility.[101]
Among other recommendations, the panel stresses that genetic tests with uncertain clinical utility, such as genomic risk assessments, should be administered in the context of clinical trials and should be conducted in the setting of pre- and post-test counseling by experienced healthcare professionals. The panel, as well as a recent report from the Secretary’s Advisory Committee on Genetics, Health, and Society supports further research to demonstrate the clinical validity and reproducibility of genomic profiles, the establishment of a national registry for genomic tests for disease risk, and the incorporation of genomic-risk variants into prospective clinical trials.[102]
Despite a need for caution, the commercialization of GWAS results has occurred in a largely unrestricted manner. Governance of this technology lies beyond the traditional scope of the US Food and Drug Administration, and as a result for-profit companies have been able to market SNP panels directly to the public. For conditions such as hair color or even ancestry determination there is possibly little harm in this approach. However, the reporting of clinically meaningless disease risk figures is worrisome. Increased risk scores with unproven clinical relevance may result in anxiety, and reduced risk scores based on preliminary data may result in incorrect reassurance regarding individual cancer risk. Individuals may consequently ignore medical advice, such as age-appropriate screening recommendations, because of a perceived reduction in risk.
The challenge of translating technological advances into patient care is not new to the field of medicine, and a well-established patient-centered model exists to optimally educate, empower, and put into effect preventive strategies. Genetic counseling is an important component of the clinical genetics model that should occur prior to genetic testing.[101,103] It details the special social, economic, and psychological ramifications of genetic and genomic information, covering the implications of testing for individuals and for their relatives.
This entire process may be omitted when genetic or genomic tests are marketed directly to consumers. Post-hoc counseling for genomic tests, however, is a different matter entirely; because the results are generally not interpretable from a clinical perspective, it is often impossible to alleviate anxiety or give advice on best management.
Conclusion
The field of preventive oncology, incorporating cancer genetics, has progressed considerably in the past decade. Management paradigms have been established for distinct syndromes that account for a significant subset of cancer predisposition. This progress has had meaningful impact on the natural history of disease affecting families worldwide. Recent technological advances that vastly improve the capacity to study genomic variation across populations have identified many associations between SNPs and a variety of malignancies. Analysis of genetic variants reviewed here, ongoing studies of structural variation, and future analysis of individual sequence differences have enormous potential to yield breakthroughs in our understanding of the genetic mechanisms of cancer susceptibility. In addition to SNPs and structural variants, microRNAs, long-range promoters, and epigenetic factors that regulate gene expression will also interact to play a part in genetic susceptibility to disease. Pending a better understanding of the complex interactions of these factors, as well as longitudinal studies of human populations that have been genetically characterized, the routine use of research-derived genomic risk panels in a clinical setting is premature. The initial harvest of information resulting from the human genome project has been substantial. However, a considerable translational effort remains before the findings of this first generation of genomic association studies can be incorporated into preventive medicine and oncologic practice.
Acknowledgments:Z.S. is supported by the Robert and Kate Niehaus Clinical Cancer Genetics Initiative at Memorial Sloan- Kettering Cancer Center. K.O. was senior author of the American Society of Clinical Oncology (ASCO) policy statement update: Genetic and genomic testing for cancer susceptibility [101]; the views expressed in this article are not those of ASCO.
Financial Disclosure:The authors have no significant financial interest or other relationship with the manufacturers of any products or providers of any service mentioned in this article.
References:
References
1. Manolio TA, Brooks LD, Collins FS: A HapMap harvest of insights into the genetics of common disease. J Clin Invest 118:1590-1605, 2008.
2. Lichtenstein P, Holm NV, Verkasalo PK, et al: Environmental and heritable factors in the causation of cancer--analyses of cohorts of twins from Sweden, Denmark, and Finland. N Engl J Med 343:78-85, 2000.
3. Goldgar DE, Easton DF, Cannon-Albright LA, et al: Systematic population-based assessment of cancer risk in first-degree relatives of cancer probands. J Natl Cancer Inst 86:1600-1608, 1994.
4. Athma P, Rappaport R, Swift M: Molecular genotyping shows that ataxia-telangiectasia heterozygotes are predisposed to breast cancer. Cancer Genet Cytogenet 92:130-134,1996.
5. Bernstein JL, Bernstein L, Thompson WD, et al: ATM variants 7271T>G and IVS10-6T>G among women with unilateral and bilateral breast cancer. Br J Cancer 89:1513-1516, 2003.
6. Bretsky P, Haiman CA, Gilad S, et al: The relationship between twenty missense ATM variants and breast cancer risk: The Multiethnic Cohort. Cancer Epidemiol Biomarkers Prev 12:733-738, 2003.
7. CHEK2 Breast Cancer Case-Control Consorrtium: CHEK2*1100delC and susceptibility to breast cancer: A collaborative analysis involving 10,860 breast cancer cases and 9,065 controls from 10 studies. Am J Hum Genet 74:1175-1182, 2004.
8. Meijers-Heijboer H, van den Ouweland A, Klijn J, et al: Low-penetrance susceptibility to breast cancer due to CHEK2(*)1100delC in noncarriers of BRCA1 or BRCA2 mutations. Nat Genet 31:55-59, 2002.
9. Thompson D, Seal S, Schutte M, et al: A multicenter study of cancer incidence in CHEK2 1100delC mutation carriers. Cancer Epidemiol Biomarkers Prev 15:2542-2545, 2006.
10. Seal S, Thompson D, Renwick A, et al: Truncating mutations in the Fanconi anemia J gene BRIP1 are low-penetrance breast cancer susceptibility alleles. Nat Genet 38:1239-1241, 2006.
11. Rahman N, Seal S, Thompson D, et al: PALB2, which encodes a BRCA2-interacting protein, is a breast cancer susceptibility gene. Nat Genet 39:165-167, 2007.
12. Easton DF: How many more breast cancer predisposition genes are there? Breast Cancer Res 1:14-147, 1999.
13. Lander ES: The new genomics: Global views of biology. Science 274:536-539, 1996.
14. Xiong M, Guo SW: Fine-scale genetic mapping based on linkage disequilibrium: Theory and applications Am J Hum Genet 60:1513-1531, 1997.
15. Frazer KA, Ballinger DG, Cox DR, et al: A second generation human haplotype map of over 3.1 million SNPs. Nature 449:851-8561, 2007.
16. Kruglyak L: The road to genome-wide association studies. Nat Rev Genet 9:314-318, 2008.
17. Satagopan JM, Elston RC: Optimal two-stage genotyping in population-based association studies. Genet Epidemiol 25:149-157, 2003.
18. Wang WY, Barratt BJ, Clayton DG, et al: Genome-wide association studies: Theoretical and practical concerns. Nat Rev Genet 6:109-6118, 2005.
19. Garcia-Closas M, Chanock S. Genetic susceptibility loci for breast cancer by estrogen receptor status. Clin Cancer Res 14:8000-8009, 2008.p>
20. Ardlie KG, Lunetta KL, Seielstad M: Testing for population subdivision and association in four case-control studies. Am J Hum Genet 71:304-311, 2002.
21. Wacholder S, Rothman N, Caporaso N: Counterpoint: Bias from population stratification is not a major threat to the validity of conclusions from epidemiological studies of common polymorphisms and cancer. Cancer Epidemiol Biomarkers Prev 11:513-520, 2002.
22. Marchini J, Cardon LR, Phillips MS, et al: The effects of human population structure on large genetic association studies. Nat Genet 36:512-517, 2004.
23. Freedman ML, Reich D, Penney KL, et al: Assessing the impact of population stratification on genetic association studies. Nat Genet 36:388-393, 2004.
24. Price AL, Patterson NJ, Plenge RM, et al: Principal components analysis corrects for stratification in genome-wide association studies. Nat Genet 38:904-909, 2006.
25. Easton DF, Pooley KA, Dunning AM, et al: Genome-wide association study identifies novel breast cancer susceptibility loci. Nature 447:1087-1093, 2007.
26. Garcia-Closas M, Hall P, Nevanlinna H, et al: Heterogeneity of breast cancer associations with five susceptibility loci by clinical and pathological characteristics. PLoS Genet 4:e1000054, 2008.
27. Ahmed S, Thomas G, Ghoussaini M, et al: Newly discovered breast cancer susceptibility loci on 3p24 and 17q23.2. Nat Genet 41:585-590, 2009.
28. Hunter DJ, Kraft P, Jacobs KB, et al: A genome-wide association study identifies alleles in FGFR2 associated with risk of sporadic postmenopausal breast cancer. Nat Genet 39:870-874, 2007.
29. Thomas G, Jacobs KB, Kraft P, et al: A multistage genome-wide association study in breast cancer identifies two new risk alleles at 1p11.2 and 14q24.1 (RAD51L1). Nat Genet 41:579-584, 2009.
30. Stacey SN, Manolescu A, Sulem P, et al:Common variants on chromosomes 2q35 and 16q12 confer susceptibility to estrogen receptor-positive breast cancer. Nat Genet 39:865-869, 2007.
31. Stacey SN, Manolescu A, Sulem P, et al: Common variants on chromosome 5p12 confer susceptibility to estrogen receptor-positive breast cancer. Nat Genet 40:703-706, 2008.
32. Gold B, Kirchhoff T, Stefanov S, et al: Genome-wide association study provides evidence for a breast cancer risk locus at 6q22.33. Proc Natl Acad Sci U S A 105:4340-4345, 2008.
33. Zheng W, Long J, Gao YT, et al: Genome-wide association study identifies a new breast cancer susceptibility locus at 6q25.1. Nat Genet 41:324-328, 2009.
34. Eeles RA, Kote-Jarai Z, Giles GG, et al: Multiple newly identified loci associated with prostate cancer susceptibility. Nat Genet 40:316-321, 2008.
35. Thomas G, Jacobs KB, Yeager M, et al: Multiple loci identified in a genome-wide association study of prostate cancer. Nat Genet 40:310-315, 2008.
36. Yeager M, Orr N, Hayes RB, et al: Genome-wide association study of prostate cancer identifies a second risk locus at 8q24. Nat Genet 39:645-649, 2007.
37. Yeager M, Chatterjee N, Ciampa J, et al: Identification of a new prostate cancer susceptibility locus on chromosome 8q24. Nat Genet 41:1055-1057, 2009.
38. Eeles RA, Kote-Jarai Z, Al Olama AA, et al: Identification of seven new prostate cancer susceptibility loci through a genome-wide association study. Nat Genet 41:1116-1121, 2009.
39. Gudmundsson J, Sulem P, Manolescu A, et al: Genome-wide association study identifies a second prostate cancer susceptibility variant at 8q24. Nat Genet 39:631-637, 2007.
40. Gudmundsson J, Sulem P, Rafnar T, et al: Common sequence variants on 2p15 and Xp11.22 confer susceptibility to prostate cancer. Nat Genet 40:281-283, 2008.
41. Gudmundsson J, Sulem P, Gudbjartsson DF, et al: Genome-wide association and replication studies identify four variants associated with prostate cancer susceptibility. Nat Genet 41:1122-1126, 2009.
42. Amundadottir LT, Sulem P, Gudmundsson J, et al: A common variant associated with prostate cancer in European and African populations. Nat Genet 38:652-658, 2006.
43. Freedman ML, Haiman CA, Patterson N, et al: Admixture mapping identifies 8q24 as a prostate cancer risk locus in African-American men. Proc Natl Acad Sci U S A 103:14068-14073, 2006.
44. Al Olama AA, Kote-Jarai Z, Giles GG, et al: Multiple loci on 8q24 associated with prostate cancer susceptibility. Nat Genet 41:1058-1060, 2009.
45. Sun J, Zheng SL, Wiklund F, et al: Evidence for two independent prostate cancer risk-associated loci in the HNF1B gene at 17q12. Nat Genet 40:1153-115, 2008.
46. Tomlinson I, Webb E, Carvajal-Carmona L, et al: A genome-wide association scan of tag SNPs identifies a susceptibility variant for colorectal cancer at 8q24.21. Nat Genet 39:984-988.
47. Zanke BW, Greenwood CM, Rangrej J, et al: Genome-wide association scan identifies a colorectal cancer susceptibility locus on chromosome 8q24. Nat Genet 39:989-994, 2007.
48. Tomlinson IP, Webb E, Carvajal-Carmona L, et al: A genome-wide association study identifies colorectal cancer susceptibility loci on chromosomes 10p14 and 8q23.3. Nat Genet 40:623-630, 2008.
49. Houlston RS, Webb E, Broderick P, et al: Meta-analysis of genome-wide association data identifies four new susceptibility loci for colorectal cancer. Nat Genet 40:1426-1435, 2008.
50. Tenesa A, Farrington SM, Prendergast JG, et al. Genome-wide association scan identifies a colorectal cancer susceptibility locus on 11q23 and replicates risk loci at 8q24 and 18q21. Nat Genet 40:631-637, 2007.
51. Jaeger E, Webb E, Howarth K, et al: Common genetic variants at the CRAC1 (HMPS) locus on chromosome 15q13.3 influence colorectal cancer risk. Nat Genet 40:26-28, 2008.
52. Broderick P, Carvajal-Carmona L, Pittman AM, et al: A genome-wide association study shows that common alleles of SMAD7 influence colorectal cancer risk. Nat Genet 39:1315-1317, 2007.
53. Wang Y, Broderick P, Webb E, et al. Common 5p15.33 and 6p21.33 variants influence lung cancer risk. Nat Genet 40:1407-1409, 2008.
54. McKay JD, Hung RJ, Gaborieau V, et al: Lung cancer susceptibility locus at 5p15.33. Nat Genet 40:1404-1406, 2008.
55. Amos CI, Wu X, Broderick P, et al. Genome-wide association scan of tag SNPs identifies a susceptibility locus for lung cancer at 15q25.1. Nat Genet 40:616-22, 2008.
56. Hung RJ, McKay JD, Gaborieau V, et al: A susceptibility locus for lung cancer maps to nicotinic acetylcholine receptor subunit genes on 15q25. Nature 452:633-637, 2008.
57. Liu P, Vikis HG, Wang D, et al: Familial aggregation of common sequence variants on 15q24-25.1 in lung cancer. J Natl Cancer Inst 100:1326-1330, 2008.
58. Petersen GM, Amundadottir L, Fuchs CS, et al: A genome-wide association study identifies pancreatic cancer susceptibility loci on chromosomes 13q22.1, 1q32.1 and 5p15.33. Nat Genet 42:224-228, 2010.
59. Amundadottir L, Kraft P, Stolzenberg-Solomon RZ, et al: Genome-wide association study identifies variants in the ABO locus associated with susceptibility to pancreatic cancer. Nat Genet 41:986-990, 2009.
60. Sakamoto H, Yoshimura K, Saeki N, et al: Genetic variation in PSCA is associated with susceptibility to diffuse-type gastric cancer. Nat Genet 40:730-740, 2008.
61. Cui R, Kamatani Y, Takahashi A, et al: Functional variants in ADH1B and ALDH2 coupled with alcohol and smoking synergistically enhance esophageal cancer risk. Gastroenterology 137: 1768-1775, 2009.
62. Kiemeney LA, Thorlacius S, Sulem P, et al: Sequence variant on 8q24 confers susceptibility to urinary bladder cancer. Nat Genet 40:1307-1312, 2008.
63. Wu X, Ye Y, Kiemeney LA, et al: Genetic variation in the prostate stem cell antigen gene PSCA confers susceptibility to urinary bladder cancer. Nat Genet 41:991-995, 2009.
64. Rapley EA, Turnbull C, Al Olama AA, et al: A genome-wide association study of testicular germ cell tumor. Nat Genet 41:807-810, 2009.
65. Kanetsky PA, Mitra N, Vardhanabhuti S, et al: Common variation in KITLG and at 5q31.3 predisposes to testicular germ cell cancer. Nat Genet 41:811-815, 2009.
66. Song H, Ramus SJ, Tyrer J, et al: A genome-wide association study identifies a new ovarian cancer susceptibility locus on 9p22.2. Nat Genet 41:996-1000, 2009.
67. Stacey SN, Sulem P, Masson G, et al: New common variants affecting susceptibility to basal cell carcinoma. Nat Genet 41:909-914, 2009.
68. Stacey SN, Gudbjartsson DF, Sulem P, et al: Common variants on 1p36 and 1q42 are associated with cutaneous basal cell carcinoma but not with melanoma or pigmentation traits. Nat Genet 40:1313-1318, 2008.
69. Bishop DT, Demenais F, Iles MM, et al: Genome-wide association study identifies three loci associated with melanoma risk. Nat Genet 41:920-925, 2009.
70. Gudbjartsson DF, Sulem P, Stacey SN, et al: ASIP and TYR pigmentation variants associate with cutaneous melanoma and basal cell carcinoma. Nat Genet 2008;40:886-891, 2008.
71. Brown KM, Macgregor S, Montgomery GW, et al: Common sequence variants on 20q11.22 confer melanoma susceptibility. Nat Genet 40:838-840, 2008.
72. Gudmundsson J, Sulem P, Gudbjartsson DF, et al: Common variants on 9q22.33 and 14q13.3 predispose to thyroid cancer in European populations. Nat Genet 41:460-464, 2009.
73. Capasso M, Devoto M, Hou C, et al. Common variations in BARD1 influence susceptibility to high-risk neuroblastoma. Nat Genet 41:718-23, 2009.
74. Maris JM, Mosse YP, Bradfield JP, et al: Chromosome 6p22 locus associated with clinically aggressive neuroblastoma. N Engl J Med 358:2585-2593, 2008.
75. Shete S, Hosking FJ, Robertson LB, et al: Genome-wide association study identifies five susceptibility loci for glioma. Nat Genet 41:899-904, 2009.
76. Wrensch M, Jenkins RB, Chang JS, et al: Variants in the CDKN2B and RTEL1 regions are associated with high-grade glioma susceptibility. Nat Genet 41:905-908, 2009.
77. Papaemmanuil E, Hosking FJ, Vijayakrishnan J, et al: Loci on 7p12.2, 10q21.2 and 14q11.2 are associated with risk of childhood acute lymphoblastic leukemia. Nat Genet 41:1006-1010, 2009.
78. Trevino LR, Yang W, French D, et al: Germline genomic variants associated with childhood acute lymphoblastic leukemia. Nat Genet 41:1001-1005, 2009.
79. Di Bernardo MC, Crowther-Swanepoel D, Broderick P, et al: A genome-wide association study identifies six susceptibility loci for chronic lymphocytic leukemia. Nat Genet 40:1204-1210, 2008.
80. Skibola CF, Bracci PM, Halperin E, et al:Genetic variants at 6p21.33 are associated with susceptibility to follicular lymphoma. Nat Genet 41:873-875, 2009.
81. Kilpivaara O, Mukherjee S, Schram AM, et al: A germline JAK2 SNP is associated with predisposition to the development of JAK2(V617F)-positive myeloproliferative neoplasms. Nat Genet 41:455-459, 2009.
82. Sole X, Hernandez P, de Heredia ML, et al: Genetic and genomic analysis modeling of germline c-MYC overexpression and cancer susceptibility. BMC Genomics 9:12, 2008.
83. Pomerantz MM, Ahmadiyeh N, Jia L, et al: The 8q24 cancer risk variant rs6983267 shows long-range interaction with MYC in colorectal cancer. Nat Genet 41:882-884, 2009.
84. Tuupanen S, Turunen M, Lehtonen R, et al: The common colorectal cancer predisposition SNP rs6983267 at chromosome 8q24 confers potential to enhanced Wnt signaling. Nat Genet 41:885-890, 2009.
85. Rafnar T, Sulem P, Stacey SN, et al: Sequence variants at the TERT-CLPTM1L locus associate with many cancer types. Nat Genet 41:221-227, 2009.
86. Xu J, Kibel AS, Hu JJ, et al: Prostate cancer risk associated loci in African Americans. Cancer Epidemiol Biomarkers Prev 18:2145-2149, 2009.
87. Marcus DM: The ABO and Lewis blood-group system. Immunochemistry, genetics and relation to human disease. N Engl J Med 280:994-1006, 1969.
88. Mahakali Zama A, Hudson FP, 3rd, Bedell MA: Analysis of hypomorphic KitlSl mutants suggests different requirements for KITL in proliferation and migration of mouse primordial germ cells. Biol Reprod 73:639-647, 2005.
89. Han J, Kraft P, Nan H, et al: A genome-wide association study identifies novel alleles associated with hair color and skin pigmentation. PLoS Genet 4:e1000074, 2008.
90. Janssens AC, Gwinn M, Bradley LA, et al: A critical appraisal of the scientific basis of commercial genomic profiles used to assess health risks and personalize health interventions. Am J Hum Genet 82:593-599, 2008.
91. Grosse SD, Khoury MJ: What is the clinical utility of genetic testing? Genet Med 8:448-50, 2006.
92. Burke W: Clinical validity and clinical utility of genetic tests. Curr Protoc Hum Genet Chapter 9:Unit 9 15, Jan 2009.
93. Gail MH: Value of adding single-nucleotide polymorphism genotypes to a breast cancer risk model. J Natl Cancer Inst 101:959-963, 2009.
94. Fitzgerald LM, Kwon EM, Koopmeiners JS, et al: Analysis of recently identified prostate cancer susceptibility loci in a population-based study: Associations with family history and clinical features. Clin Cancer Res 15:3231-3237, 2009.
95. Penney KL, Salinas CA, Pomerantz M, et al: Evaluation of 8q24 and 17q risk loci and prostate cancer mortality. Clin Cancer Res 15:3223-3230, 2009.
96. Wiklund FE, Adami HO, Zheng SL, et al: Established prostate cancer susceptibility variants are not associated with disease outcome. Cancer Epidemiol Biomarkers Prev 18:1659-1662, 2009.
97. Fong PC, Boss DS, Yap TA, et al: Inhibition of poly(ADP-ribose) polymerase in tumors from BRCA mutation carriers. N Engl J Med 361:123-134, 2009.
98. Andriole GL, Crawford ED, Grubb RL, 3rd, et al: Mortality results from a randomized prostate-cancer screening trial. N Engl J Med 360:1310-1319, 2009.
99. Schroder FH, Hugosson J, Roobol MJ, et al: Screening and prostate-cancer mortality in a randomized European study. N Engl J Med 360:1320-1328, 2009.
100. Kramer BS, Hagerty KL, Justman S, et al: Use of 5-alpha-reductase inhibitors for prostate cancer chemoprevention: American Society of Clinical Oncology/American Urological Association 2008 Clinical Practice Guideline. J Clin Oncol 27:1502-1516, 2009.
101. Robson ME, Storm CD, Weitzel J, et al: American Society of Clinical Oncology policy statement update: Genetic and genomic testing for cancer susceptibility. J Clin Oncol 28:893-901, 2010.
102. National Institutes of Health, Office of Biotechnology Activities: The Integration of Genetic Technologies Into Health Care and Public Health: A Progress Report and Future Directions of the Secretary’s Advisory Committee on Genetics, Health, and Society; January 2009. Available at: http://oba.od.nih.gov/SACGHS/sacghs_documents.html. Accessed December May 25, 2010.
103. Offit K, Thom P: Ethical and legal aspects of cancer genetic testing. Semin Oncol 34:435-443, 2007.







Late Hepatic Recurrence From Granulosa Cell Tumor: A Case Report
Granulosa cell tumors exhibit late recurrence and rare hepatic metastasis, emphasizing the need for lifelong surveillance in affected patients.


